SQL(Structed Query Language)이란?
SQL란 표준 관계형 데이터베이스 언어로, 관계대수와 관계해석을 기초로 한 혼합 데이터 언어입니다. 사용 용도에 따라 DDL, DCL, DML로 구분됩니다. 자세하게 다뤄볼게요!
✅ SQL에서 지원하는 기본 데이터 타입
- 정수: INTEGER(4byte), SMALLINT(2byte)
- 실수: FLOAT, REAL, DOUBLE PRECISION
-날짜: DATE
- 시간: TIME
- 형식화된 숫자: DEC(i, j) (i는 전체 자릿수, j는 소수부 자릿수)
- 가변길이 문자: VARCHAR(n), CHARACTER VARYING(n)
- 고정길이 문자: BIT(n)
- 고정길이 비트열: BIT(n)
- 가변길이 비트열: VARBIT(n)
DDL(Data Define Language): 데이터 정의어
DDL은 데이터를 정의하는 언어로서 '데이터를 담는 그릇'을 정의하는 언어로, DB 구조, 데이터 형식, 접근 방식 등 DB를 구축하거나 수정할 목적으로 사용하는 언어입니다. 번역한 결과가 데이터 사전(Data Dictionary)이라는 특별한 파일에 여러 개의 테이블로서 저장됩니다.
💡 DDL의 대상
도메인(DOMAIN): 하나의 속성이 가질 수 있는 원자값들의 집합으로, 속성의 데이터 타입과 크기, 제약조건 등의 정보를 담고 있습니다.
스키마(SCHEMA): 데이터베이스의 구조, 제약조건 등의 정보를 담고 있는 기본적인 구조로, 외부(External), 개념(Conceptual), 내부(Internal) 3계층으로 구성되어 있습니다.
테이블(TABLE): 데이터의 저장 공간입니다.
뷰(VIEW): 하나 이상의 물리 테이블에서 유도되는 가상의 테이블입니다.
인덱스(INDEX): 검색을 빠르게 하기 위한 데이터 구조입니다.
CREATE
데이터베이스 오브젝트를 생성하는 명령어입니다.
CREATE DOMAIN
도메인을 정의하는 명령문으로, 임의의 속성에서 취할 수 있는 값의 범위가 SQL에서 지원하는 전체 데이터 타입의 값이 아니고 일부분일 때, 그 값의 범위를 도메인으로 정하게 됩니다. 정의된 도메인명은 일반적인 데이터 타입처럼 사용합니다.
📋 예를 들어 학년 속성의 데이터 타입이 정수형이고, 해당 속성에서 취할 수 있는 값의 범위가 1부터 4까지라면, 이 범위를 해당 속성의 도메인으로 정의해서 사용할 수 있습니다.
쉽게 말해서 도메인은 특정 속성에서 사용할 데이터의 범위를 사용자가 정의하는 사용자 정의 데이터 타입입니다.
CREATE DOMAIN GRADE [AS] INTEGER -- GRADE라는 이름의 정수형 사용자 데이터 타입 정의
DEFAULT 1 -- 기본값: 데이터를 입력하지 않았을 때 자동으로 입력되는 값
CONSTRAINT VALID-GENDER CHECK(VALUE >= 1 AND VALUE <= 4));CREATE SCHEMA
스키마를 정의하는 명령문으로, 스키마의 식별을 위해 스키마의 이름과 소유권자 혹은 허가권자를 정의합니다.
CREATE SCHEMA 대학교 AUTHORIZATION 홍길동; -- 사용자 ID가 '홍길동'인 스키마 '대학교'를 정의함✅ 스키마는 데이터베이스의 구조와 제약 조건에 관한 전반적인 명세를 기술한 것으로 데이터 개체, 속성, 관계 및 데이터 조작 시 데이터 값들이 갖는 제약 조건 등에 관해 전반적으로 정의합니다.
CREATE TABLE
테이블을 정의하는 명령문으로, 테이블 내 속성들의 속성명, 데이터 타입, 기본값, NOT NULL 여부 등을 지정합니다.
| 설명 | |
| DEFAULT | 데이터를 입력하지 않았을 때 자동으로 입력되는 값을 설정합니다. |
| NOT NULL | 특정 속성이 데이터 없이 비어 있어서는 안 된다는 것을 지정할 때 사용합니다. |
| PRIMARY KEY | 기본키로 사용할 속성 또는 속성의 집합을 지정합니다. |
| UNIQUE | 대체키로 사용할 속성 또는 속성의 집합을 지정하는 것으로 중복된 값을 가질 수 없습니다. |
| FOREIGN KEY ~ REFERENCES ~ |
참조할 다른 테이블과 그 테이블을 참조할 때 사용할 외래키 속성을 지정합니다. 외래키가 지정되면 참조 무결성의 CASCADE 법칙이 적용됩니다. |
| ON DELETE: 참조 테이블의 튜플이 삭제되었을 때 기본 테이블에 취해야 할 사항을 지정합니다. ON UPDATE: 참조 테이블에 참조 속성 값이 변경되었을 때 기본 테이블에 취해향 할 사항을 지정합니다. |
|
| NO ACTION: 참조테이블에 변화가 있어도 기본 테이블에는 아무런 조치를 취하지 않습니다. CASCADE: 참조 테이블의 튜플이 삭제되면 기본 테이블의 관련 튜플도 모두 삭제되고, 속성이 변경되면 관련 튜플의 속성 값도 모두 변경됩니다. SET NULL: 참조 테이블에 변화가 있으면 기본 테이블의 관련 튜플의 속성 값을 NULL로 변경합니다. SET DEFAULT: 참조 테이블에 변화가 있으면 기본 테이블의 관련 튜플의 속성 값을 기본값으로 변경합니다. |
|
| CONSTRAINT | 제약 조건의 이름을 지정합니다. |
| CHECK | 속성 값에 대한 제약 조건을 정의합니다. |
📋 예를 들어 '이름', '학번', '번호', '전공', '성별', '생년월일'로 구성된 <학생> 테이블을 정의하려고 합니다.
[제약 조건]
- '이름'은 NULL이 올 수 없고 '학번'은 기본키, '번호'는 대체키입니다.
- '전공'은 <학과> 테이블의 '학과코드'를 참조하는 외래키로 사용되는데,
<학과> 테이블에서 삭제가 일어나면 관련된 튜플들의 전공 값을 NULL로 만들고,
'학과코드'가 변경되면 전공 값도 같은 값으로 변경합니다.
- '생년월일'은 1980-01-01 이후의 데이터만 저장할 수 있습니다.
- 각 속성의 테이터 타입은 적당하게 지정하되, '성별'은 도메인 'GENDER'를 사용합니다.
CREATE TABLE 학생
(이름 VARCHAR(15) NOT NULL,
학번 CHAR(8),
번호 CHAR(20),
전공 CHAR(5),
성별 GENDER DEFALT '남',
생년월일 DATE,
PRIMARY KEY(학번),
UNIQUE(번호),
FORIEGN KEY(전공) REFERENCES 학과(학과코드)
ON DELETE SET NULL
ON UPDATE CASCADE,
CONSTRAINT 생년월일제약 CHECK(생년월일>='1980-01-01'));CREATE VIEW
뷰를 정의하는 명령문으로, SELECT문을 서브 쿼리(조건절에 주어진 질의)로 사용하여 SELECT문의 결과로서 뷰를 생성합니다. 단, SELECT문에는 UNION(성격이 유사한 두 개의 테이블 데이터를 하나로 만드는 합집합 연산자)이나 ORDER BY절(특정 속성을 기준으로 정렬하여 검색할 때 사용)을 사용할 수 없습니다.
📋 에를 들어 <고객> 테이블에서 '주소'가 '인천시'인 고객들의 '성명'과 '전화번호'를 '인천고객'이라는 뷰로 정의하려고 합니다.
CREATE VIEW 인천고객(성명, 전화번호)
AS SELECT 성명, 전화번호 FROM 고객 WHERE 주소 = '인천시';CREATE INDEX
인덱스를 정의하는 명령문으로, UNIQUE가 사용된 경우 중복 값을 허용하지 않습니다. ASC(오름차순 정렬 - 기본값), DESC(내림차순 정렬)를 통해 정렬 여부를 지정할 수 있입니다. CLUSTER를 사용하면 인덱스가 클러스터드 인덱스로 설정됩니다.
💡 클러스터드 인덱스(Clustered Index)
인덱스 키의 순서에 따라 데이터가 정렬되어 저장되는 방식으로, 실제 데이터가 순서대로 저장됩니다. 원하는 데이터를 빠르게 찾을 수 있다는 장점이 있지만, 데이터 삽입, 삭제 발생 시 순서를 유지하게 위해 매번 데이터를 재정렬해야 한다는 단점이 있습니다.
vs 넌클러스터드 인덱스(Non-Clustered Index)
인덱스의 키 값만 정렬되어 있을 뿐 실제 데이터는 정렬되지 않는 방식입니다. 데이터를 검색하기 위해서는 먼저 인덱스를 검색하여 실제 데이터의 위치를 확인해야 합니다.
📋 예를 들어 <학생> 테이블에서 UNIQUE한 특성을 갖는 '학번' 속성에 대해 내림차순으로 정렬하여 '학번_idx'라는 이름으로 인덱스를 정의하려고 한다.
CREATE UNIQUE INDEX 학번_idx
ON 학생(학번 DESC);
ALTER
데이터베이스 오브젝트를 변경하는 명령어입니다.
ALTER TABLE
| ADD | 새로운 속성을 추가할 때 사용합니다. |
| ALTER | 특정 속성의 DEFAULT 값을 변경할 때 사용합니다. |
| DROP COLUMN | 특정 속성을 삭제할 때 사용합니다. CASCADE: 기본키 혹은 대체키를 삭제하면 이를 참조하는 모든 외래 키가 함께 삭제됩니다. RESTRICT: 삭제하려는 키의 외래키 참조가 존재하면 오류가 반환됩니다. |
📋 <학생> 테이블에 최대 3문자로 구성되는 '학년' 속성을 추가,
'학번' 속성의 데이터 타입과 크기를 VARCHAR(10)으로 하고 NULL 값이 입력되지 않도록 변경,
'번호' 속성을 삭제하려고 합니다. 단, 이 속성을 참조하고 있는 모든 참조키를 함께 삭제합니다.
ALTER TABLE 학생 ADD 학년 VARCHAR(3);
ALTER TABLE 학생 ALTER 학번 VARCHAR(10) NOT NULL;
ALTER TABLE 학생 DROP COLUMN 번호 CASCADE;ALTER INDEX
인덱스를 수정하는 명령어로, 기존 인덱스를 삭제하고 신규 인덱스를 생성하는 방식으로 사용을 권고하기 때문에 일부 DBMS에는 제공하지 않습니다.
📋 예를 들어 <사원> 테이블의 '사번' 컬럼에 대해 '사번인덱스'라는 인덱스 명으로 인덱스를 수정하려고 합니다.
ALTER INDEX 사번인덱스 ON 사원(사번);
DROP/TRUNCATE TABLE
DROP TABLE은 테이블을 삭제하는 명령이고, TRUNCATE TABLE은 테이블 내의 데이터들을 삭제하는 명령입니다.
📋 예를 들어 <사원> 테이블을 제거하되 다른 테이블에서의 외래 참조가 존재한다면 제거를 취소하도록 하고,
<학생> 테이블 내의 모든 데이터를 삭제하려고 합니다.
DROP TABLE 사원 RESTRICTED;
TRUNCATE TABLE 학생;
DCL(Data Control Language): 데이터 제어어
DCL은 데이터의 보안, 무결성, 회복, 병행 제어 등을 정의하는 데 사용하는 언어입니다. 주로 일반 사용자보다는 데이터베이스 관리자(DBA)가 데이터 관리를 목적으로 사용합니다. GRANT, REVOKE, COMMIT, ROLLBACK, SAVEPOINT 등이 있습니다.
GRANT/REVOKE
데이터베이스 관리자가 데이터베이스 사용자에게 사용자등급을 지정(GRANT)하거나 해제(REVOKE)하기 위한 명령어입니다.
✅ 사용자등급
- DBA: 데이터베이스 관리자
- RESOURCE: 데이터베이스 및 테이블 생성 가능자
- CONNECT: 단순 사용자
📋 예를 들어 "HONG"이라는 사람에게 데이터베이스 및 테이블을 생성할 수 있는 권한을 부여,
"KIM"이라는 사람에게 단순히 데이터베이스에 있는 정보를 검색할 수 있는 권한을 부여,
단순 사용자인 "LEE"라는 사람에게 권한을 회수하고자 합니다.
GRANT RESOURCE TO HONG;
GRANT CONNECT TO KIM;
REVOKE CONNECT TO LEE;
DML(Data Manipulation Language): 데이터 조작어
DML은 데이터베이스에 저장된 자료들을 입력, 조회, 수정, 삭제(CRUD)하는 언어입니다. 데이터베이스 사용자가 응용 프로그램이나 질의어를 통해 저장된 데이터를 실질적으로 관리하는데 사용되는 언어입니다. 데이터베이스 사용자와 데이터베이스 관리 시스템 간의 인터페이스를 제공한다는 특징이 있습니다.
INSERT INTO ~ [VALUES]
삽입문은 테이블에 새로운 튜플을 삽입할 때 사용합니다. 대응하는 속성과 데이터는 개수와 데이터 유형이 일치해야 하며, 기본 테이블의 모든 속성을 사용할 때는 속성명을 생략할 수 있습니다.
📋 예를 들어 <학생>테이블에 '이름'이 '고길동', 학번이 '220001"인 학생을 삽입하려고 합니다.
INSERT INTO 학생(이름, 학번) VALUES('고길동', '220001');SELECT문을 사용하여 다른 테이블의 검색 결과를 삽입할수도 있습니다.
📋 예를 들어 <사원> 테이블에 있는 '개발' '부서'의 모든 튜플을 개발부원(이름, 급여) 테이블에 삽입하려고 합니다.
INSERT INTO 개발부원(이름, 급여)
SELECT 이름, 급여 FROM 사원 WHERE 부서 = '개발';UPDATE ~ SET ~ [WHERE]
갱신문은 특정 튜플의 내용을 변경할 때 사용합니다.
📋 예를 들어 <사원> 테이블에서 '김길동'의 '부서'를 '디자인'으로 변경하고 '기본급'을 10만원 인상시키려고 합니다.
UPDATE 사원
SET 부서 = '디자인', 기본급 = 기본급 + 10
WHERE 이름 = '김길동';DELETE ~ FROM ~ [WHERE]
삭제문은 특정 튜플을 삭제할 때 사용하는데, 모든 레코드를 삭제할 때는 WHERE절을 생략합니다.
✅ DELETE, TRUCNATE, DROP 비교
DELETE 명령어는 모든 레코드를 삭제하더라도 테이블 구조는 남아있어 용량이 줄어 들지 않고, COMMIT전에 되돌릴 수 있습니다. 따라서 데이터를 모두 삭제하여 용량이 줄어드는 TRUNCATE와 다르고, 디스크에서 테이블을 완전히 제거하는 DROP과 다릅니다. (TRUNCATE, DROP - 되돌릴 수 없음)
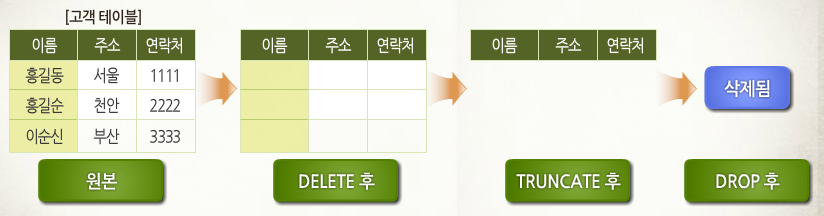
📋 예를 들어 <학생> 테이블에서 학과가 '컴퓨터'인 모든 튜플을 삭제하고자 합니다.
DELETE FROM 학생
WHERE 학과 = '컴퓨터';
SELECT ~ FROM ~
데이터의 내용을 조회할 때 사용하는 명령어로 실무에서 가장 많이 사용되는 명령어입니다.
| SELECT | 검색하고자 하는 속성명 혹은 계산식을 기술합니다. 속성명은 AS를 사용하며 키워드는 생략 가능합니다. ALL: 모든 튜플을 검색할 때 지정하는 것으로 기본값이라 생략이 가능합니다. DISTINCT: 중복된 튜플이 있으면 그 중 첫 번째 한 개만 검색합니다. DISTINCTROW: 중복된 튜플을 제거하고 한 개만 검색하지만 선택된 속성의 값이 아닌, 튜플 전체를 대상으로 합니다. |
| FROM | 질의에 의해 검색될 데이터들을 포함하는 테이블 명을 기술합니다. |
| WHERE | 검색할 조건을 기술합니다. |
| GROUP BY | 속성값을 그룹으로 분류하고자 할 때 사용합니다. |
| HAVING | GROUP BY에 의해 분류한 후 그룹에 대한 조건을 지정합니다. |
| ORDER BY | 특정 속성을 기준으로 정렬하여 검색할 때 사용합니다. (ASC/DESC) |
❓ HAVING과 WHERE의 차이점은 무엇인가요?
- HAVING은 그룹을, WHERE은 개별 튜플에 대한 조건을 지정합니다.
- HAVING은 그룹화 또는 집계가 발생 한 후, WHERE은 그룹화 또는 집계가 발생하기 전에 필터링을 하게 됩니다.
- 집계 함수(COUNT, SUM, AVG, MAX, MIN 등)는 HAVING과 함께 사용할 수 있으나, WEHRE과는 함께 사용할 수 없습니다.
- HAVING은 SELECT문에서만 사용되며 일반적으로 GROUP BY와 함께 사용됩니다. GROUP BY 절이 사용되지 않으면 HAVING은 WHERE 절처럼 동작합니다.
기본 검색 (SELECT ~ FROM ~)
📋 예를 들어 <사원> 테이블의 모든 튜플을 검색하려고 합니다.
SELECT 이름, 부서, 생일, 주소, 기본급 FROM 사원; -- 1
SELECT 사원.이름, 사원.부서, 사원.생일, 사원.주소, 사원.기본급 FROM 사원; -- 2
SELECT 사원.* FROM 사원; -- 3
SELECT * FROM 사원; -- 4📋 예를 들어 <사원> 테이블에서 '주소'만 검색하되 같은 '주소'는 한 번만 출력하고자 합니다.
SELECT DISTINCT 주소 FROM 사원;
조건 지정 검색 (SELECT ~ FROM ~ WHERE)
| 비교 | =, <>, !=, <, <=, >, >= |
| 범위 | BETWEEN ~ AND ~ |
| 집합 | IN, NOT IN |
| 패턴 | LIKE - %: 0개 이상의 문자열과 일치 - _: 1개의 문자와 일치 - #: 1개의 숫자와 일치 - [ ]: 1개의 문자와 일치 ex) [ABCD]%: 첫글자가 A, B, C, D 중 하나인 문자열 검색 - [^]:1개의 문자와 불일치 |
| NULL | IS NULL, IS NOT NULL |
| 복합조건 | AND, OR, NOT, ! |
📋 예를 들어 <사원> 테이블에서 '생일'이 '01/01/93'에서 '12/31/99' 사이인 튜플을 검색하고자 합니다.
SELECT * FROM 사원
WHERE 생일 BETWEEN '01/01/93' AND '12/31/99';📋 예를 들어 <성적> 테이블에서 '학점'이 B-이상인 튜플을 검색하고자 합니다.
SELECT * FROM 성적
WHERE 학점 LIKE '[AB]%';
정렬 검색 (SELECT ~ FROM ~ ORDER BY)
📋 예를 들어 <성적> 테이블에서 '학점'을 기준으로 내림차순 정렬하고, 같은 '학점'에 대해서는 '이름'을 기준으로 오름차순 정렬시켜서 검색하고자 합니다.
SELECT * FROM 성적
ORDER BY 학점 DESC, 이름 ASC;
서브쿼리 (Sub-Quary)
서브쿼리는 SQL문 안에 포함된 또 다른 SQL문입니다. 서브쿼리의 용도는 알려지지 않은 기준을 위한 검색을 위함입니다. 메인쿼리와 서브쿼리는 주종 관계로서, 서브쿼리에 사용되는 컬럼 정보는 메인 쿼리의 컬럼 정보를 사용할 수 있으나 역으로는 성립하지 않습니다.
| SELECT절 서브쿼리 | 스칼라(Scalar: 한번에 한 가지만 처리하는) 서브쿼리로, 반드시 단일 행을 리턴해야 합니다. 따라서 SUM, COUNT, MIN, MAX 등과 같은 집계 함수가 많이 쓰입니다. |
| FROM절 서브쿼리 | 인라인 뷰(Inline View)로, 뷰처럼 결과가 동적으로 생성된 테이블 형태로 사용할 수 있습니다. |
| WHERE절 서브쿼리 | 서브쿼리가 WHERE절 안에 들어있는 형태로, 중첩(Nested) 서브쿼리라고 불립니다. |
✅ 집계 함수
여러 행 또는 테이블 전체 행으로부터 하나의 결괏값을 반환하는 함수입니다.
COUNT, SUM, AVG, MAX, MIN, STDDEV(표준편차), VARIANCE(분산)
📋 예를 들어 <도서> 테이블의 '책명'이 '자료구조'인 책 중에서 '책번호'가 <도서가격> 테이블의 '책번호'와 같고 '가격'이 가장 큰 값을 조회하고자 합니다.
SELECT MAX(가격) FROM 도서가격
WHERE 책번호 IN (SELECT 책번호 FROM 도서 WHERE 책명 = '자료구조');
그룹 지정 검색 (SELECT ~ FROM ~ GROUP BY ~ [HAVING])
특정 열이나 연산한 결과를 집계 키로 정의하여 그 집계 키의 Unique 값에 따라 그룹을 짓는 역할을 합니다.
📋 예를 들어 <상여금> 테이블에서 '금액'이 100 이상이 사원이 2명 이상인 부서의 튜플 수를 구하고자 합니다.
SELECT 부서, COUNT(*) AS 사원수 FROM 상여금
WHERE 금액 >= 100
GROUP BY 부서 HAVING 사원수 >= 2;💡 그룹 함수
테이블의 전체 행을 하나 이상의 컬럼을 기준으로 컬럼 값에 따라 그룹화하여 그룹별로 결과를 출력하는 함수입니다.
- ROLLUP: 인수로 주어진 속성을 대상으로 하위 레벨에서 상위 레벨 순(N + 1 ~ 1)으로 그룹별 소계를 구하는 함수입니다. 인수의 순서에 따라 결괏값이 다릅니다.
- CUBE: 인수로 주어진 속성을 대상으로 모든 조합의 그룹별 소계를 상위 레벨에서 하위 레벨 순(1 ~ N^2)으로 구하는 함수입니다. 인수의 순서에 따라 결괏값이 다릅니다.
- GROUPING SET: 인수로 주어진 속성을 대상으로 개별 집계를 구하는 함수로, 인수의 순서와 결과는 무관합니다.
📋 예를 들어 <DEPT_SALARY> 테이블에서 'DEPT' 부서, 'JOB' 직위, 그리고 'SALARY' 연봉에 대해 부서별, 직위별 소계와 전체 합계를 '급여합계'라는 이름으로 나타내도록 조회하고자 합니다.
SELECT DEPT, JOB, SUM(SALARY) AS 연봉합계 FROM DEPT_SALARY
GROUP BY ROLLUP(DEPT, JOB);
WINDOW 함수 이용 검색 (SELECT ~ OVER ~ FROM ~ )
WINDOW 함수란 GROUP BY절을 이용하지 않고 속성의 값을 집계할 수 있는 함수입니다. 데이터베이스를 사용한 온라인 분석 처리 용도로 사용하기 위해 표준 SQL에 추가된 함수로, OLAP(OnLine Analytical Processing)이라고도 불립니다.
- PARTITION BY: WINDOW 함수가 적용될 범위로 사용할 속성을 지정합니다.
- ORDER BY: PARTITION 안에서 정렬 기준으로 사용할 속성을 지정합니다.
| 순위 함수 | - RANK: 윈도우별 순위를 반환하는 함수로, 공동 순위를 반영합니다. - DENSE_RANK: 윈도우별 순위를 반환하는 함수로, 공동 순위를 무시하고 차례로 순위를 부위합니다. - ROW_NUMBER: 윈도우별 각 레코드에 대한 일련(연속) 번호를 부여합니다. |
| 행 순서 함수 | - FIRST_VALUE: 윈도우에서 가장 먼저 나오는 값을 찾는 함수입니다. - LAST_VALUE: 윈도우에서 가장 늦게 나오는 값을 찾는 함수입니다. - LAG: 윈도우에서 이전 로우의 값을 반환하는 함수입니다. - LEAD: 윈도우에서 이후 로우의 값을 반환하는 함수입니다. |
| 그룹 내 비율 함수 | - RATIO_TO_PERCENT: 주어진 그룹에 대해 합을 기준으로 상대적 비율을 반환하는 함수로, 0~1 범위의 결과값을 가집니다. - PERCENT_RANK: 주어진 그룹에 대해 제일 먼저 나오는 것을 0, 제일 늦게 나오는 것을 1로 하여, 값이 아닌 행의 순서별 백분율을 구하는 함수입니다. 0~1 범위의 결과값을 가집니다. |
📋 예를 들어 <학점>테이블에서 '과목'별로 '학점'에 대한 순위를 구하고자 합니다. 단 순서는 오름차순이고, 속성명은 '학점순위'로 하며 공동 순위를 반영합니다.
SELECT 과목, 학점, RANK() OVER(
PARTITION 과목 ORDER BY 학점 ASC) AS 학점순위 FROM 성적;🍯 SQL 실제 실행 순서
FROM, ON, JOIN > WHERE > GROUP BY > CUBE | ROOLUP > HAVING > SELECT > DISTINCT > ORDER BY > LIMIT
SQL 쿼리에는 실행하는 데 순서가 존재합니다. 이 순서에 의해서 쿼리가 처리되고 어떻게 쿼리문을 작성하느냐에 따라 퍼포먼스의 차이가 발생합니다. 이는 문법 순서와는 다르며, 실행 순서를 알면 효율적인 쿼리를 짜는데 도움이 됩니다.
절차형 SQL
C, JAVA 등의 프로그래밍 언어와 같이 연속적인 실행이나 분기, 반복 등의 제어가 가능한 SQL을 의미합니다.
프로시저(Procedure)
프로시저는 일련의 쿼리들을 마치 하나의 함수처럼 실행하기 위한 쿼리의 집합입니다. 절차형 SQL을 활용하여 특정 기능을 수행하는 일종의 트랜잭션 언어로, 호출을 통해 실행되어 미리 저장해 놓은 SQL 작업을 수행합니다. 프로시저를 만들어 데이터베이스에 저장하면 여러 프로그램에서 호출하여 사용할 수 있습니다. 주로 일일 마감 작업, 일괄(Batch) 작업 등에 사용됩니다.
변수 및 상수를 선언할 수 있고, IF문, LOOP문 등 제어문을 사용하고 DML, DCL 명령문으로 데이터베이스를 제어합니다. 프로시저를 실행할 때는 EXECUTE, EXEC, CALL 명령어(+ 프로시저명;)을 사용하고 프로시저를 제거할 때는 DROP PROCEDURE(+ 프로시저명;)을 사용합니다.
✅ 저장 프로시저의 장/단점
장점
- SQL문을 캡슐화하여 여러 곳에서 재사용할 수 있습니다.
- 네트워크 소요 시간을 줄일 수 있습니다.
- 협업 시 프로시저를 API처럼 배포하여 역할을 구분하여 개발이 가능합니다.
단점
- 배포 절차가 따로 없어 유지보수 및 이력 관리가 힘듭니다.
- 코드가 길어지면 스파게티 코드일 확률이 높아져서 로직 파악이 어렵습니다. (디버깅 어려움)
- 프로시저 내부에 연산이 포함될 경우 CPU 점유율이 높아지고 실행 시간도 길어지므로, LOCK이 걸려있을 경우 병목이 될 확률이 높아집니다.
사용자 정의 함수
프로시저와 유사하게 SQL을 사용하여 일련의 작업을 연속적으로 처리하며, 종료 시 처리 결과를 단일값으로 반환하는 절차형 SQL입니다. 예약어 RETURN을 통해 값을 반환하기 때문에 출력 파라미터가 없습니다.
데이터베이스에 저장되어 DML문 호출에 의해 실행됩니다. DBMS에 기본적으로 포함되어 있는 내장 함수처럼 DML문에서 반환 값을 활용하기 위한 용도로 사용됩니다.
함수 내에서 테이블 조작은 SELECT를 통한 조회만 가능하고, 프로시저를 호출하여 사용할 수 없습니다.
| 프로시저 | 사용자 정의 함수 | |
| 반환값 | 없거나 1개 이상 가능 | 1개 |
| 파라미터 | 입/출력 가능 | 입력만 가능 |
| 사용 가능 명령문 | DML, DCL | SELECT |
| 호출 | 프로시저, 사용자 정의 함수 | 사용자 정의 함수 |
| 사용 방법 | 실행문 | DML에 포함 |
SQL 코딩테스트 문제 풀이
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
SELECT ANIMAL_TYPE, COUNT(ANIMAL_TYPE) as count FROM ANIMAL_INS
GROUP BY ANIMAL_TYPE
ORDER BY ANIMAL_TYPE ASC프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
SELECT MIN(DATETIME) as 시간 FROM ANIMAL_INS'All Categories > CS' 카테고리의 다른 글
| [DB] SQL vs NoSQL - 차이점, 특징, 비교 (5) | 2022.10.03 |
|---|---|
| [DB] SQL 튜닝 (5) | 2022.09.19 |
| [DB] Join - 논리적 조인(Inner, Outer, Cross, Self), 물리적 조인(Nested Loop, Sort Merge, Hash) (6) | 2022.08.30 |
| [DB] DB 기본 개념 (+key) - 면접 예상 질문 & 답변 (1) | 2022.08.07 |



